Accepted Papers
Label-Free Model Failure Detection for Lidar-based Point Cloud Segmentation

Authors: Daniel Bogdoll, Finn Sartoris, Vincent Geppert, Svetlana Pavlitska, and J. Marius Zöllner
Affiliations:
FZI Research Center for Information Technology, Germany
Karlsruhe Institute of Technology, Germany
Abstract: Autonomous vehicles drive millions of miles on the road each year. Under such circumstances, deployed machine learning models are prone to failure both in seemingly normal situations and in the presence of outliers. However, in the training phase, they are only evaluated on small validation and test sets, which are unable to reveal model failures due to their limited scenario coverage. While it is difficult and expensive to acquire large and representative labeled datasets for evaluation, large-scale unlabeled datasets are typically available. In this work, we introduce label-free model failure detection for lidar-based point cloud segmentation, taking advantage of the abundance of unlabelled data available. We leverage different data characteristics by training a supervised and self-supervised stream for the same task to detect failure modes. We perform a large-scale qualitative analysis and present LidarCODA, the first publicly available dataset with labeled anomalies in real-world lidar data, for an extensive quantitative analysis.
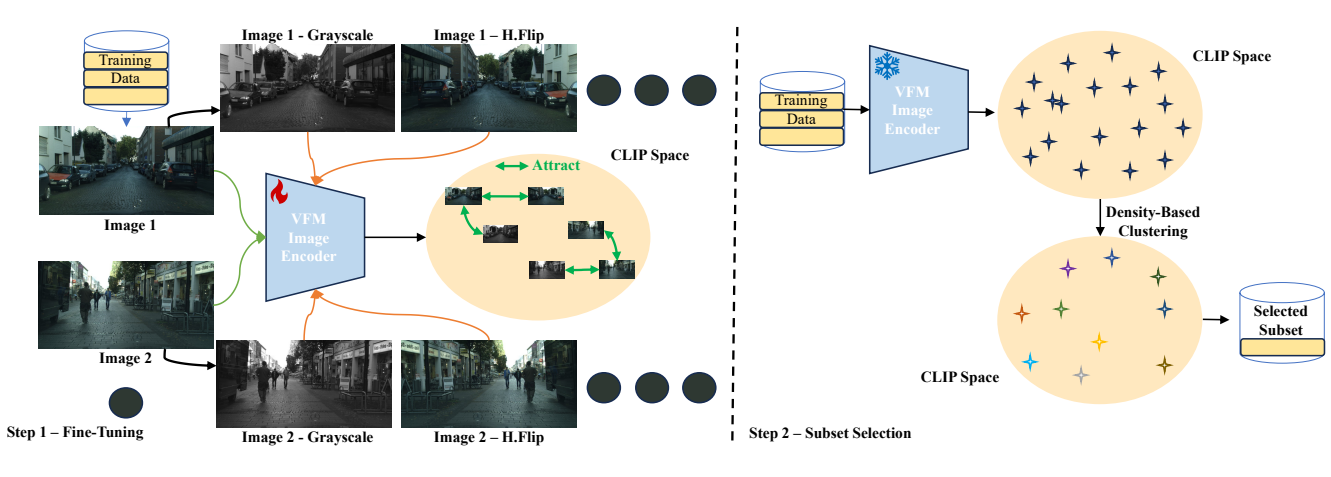
Subset Selection for Autonomous Driving Datasets via Fine-Tuning Vision Foundation Models
Authors: Mert Keser, Sinan Simsek, Deniz Karacor, and Alois Knoll
Affiliations:
Technical University of Munich, Germany
Continental AG, Germany Baskent University, Turkiye
Abstract: Training large-scale vision models for autonomous driving is computationally expensive and requires extensive manual annotation. While reducing dataset size could address these limitations, it typically results in degraded model performance. In this paper, we propose a novel self-supervised data selection framework that leverages vision foundation models to identify and retain high-value training samples, enabling efficient dataset curation without compromising performance. Our approach fine-tunes a foundation model’s vision encoder using a contrastive objective, then perform density-based clustering in its learned embedding space to retain only those samples that maximally preserve semantic diversity. Through experiments, we show that training on our curated subset outperforms models trained on the full dataset, and exceeds random selection in semantic segmentation tasks. Additionally, our comparisons across different foundation model architectures and segmentation backbones provide insights into effective dataset curation. Our results highlight that self-supervised data selection can significantly reduce both annotation and computational overhead, providing a scalable alternative to naively expanding datasets.
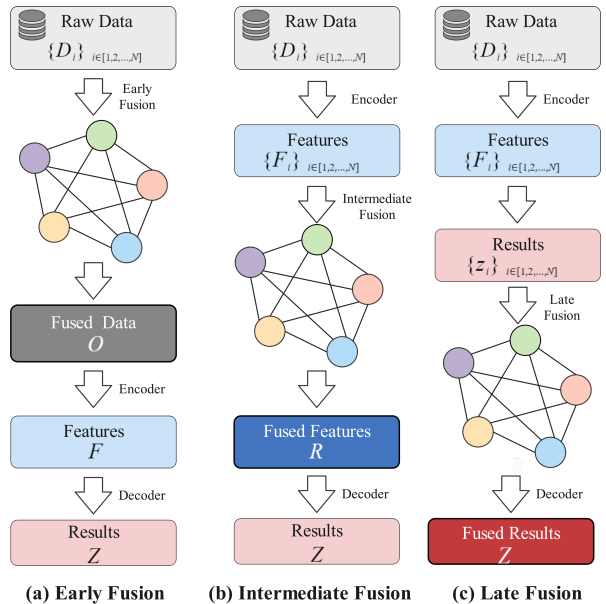
Integrating Multi-Modal Sensors: A Review of Fusion Techniques for Intelligent Vehicles
Authors: Chuheng Wei, Ziye Qin, Ziyan Zhang, Guoyuan Wu, and Matthew J. Barth
Affiliations:
University of California, Riverside, USA
Southwest Jiaotong University, Chengdu, China
Abstract: Multi-sensor fusion plays a critical role in enhancing perception for autonomous driving, overcoming individual sensor limitations, and enabling comprehensive environmental understanding. This paper first formalizes multi-sensor fusion strategies into data-level, feature-level, and decision-level categories and then provides a systematic review of deep learning-based methods corresponding to each strategy. We present key multi-modal datasets and discuss their applicability in addressing real-world challenges, particularly in adverse weather conditions and complex urban environments. Additionally, we explore emerging trends, including the integration of Vision-Language Models (VLMs), Large Language Models (LLMs), and the role of sensor fusion in end-to-end autonomous driving, highlighting its potential to enhance system adaptability and robustness. Our work offers valuable insights into current methods and future directions for multi-sensor fusion in autonomous driving.
Inconsistency-based Active Learning for LiDAR Object Detection

Authors: Esteban Rivera, Loic Stratil, and Markus Lienkamp
Affiliations:
Technical University of Munich, Germany
Abstract: Deep learning models for object detection in autonomous driving have recently achieved impressive performance gains and are already being deployed in vehicles worldwide. However, current models require increasingly large datasets for training. Acquiring and labeling such data is costly, necessitating the development of new strategies to optimize this process. Active learning is a promising approach that has been extensively researched in the image domain. In our work, we extend this concept to the LiDAR domain by developing several inconsistency-based sample selection strategies and evaluate their effectiveness in various settings. Our results show that using a naive inconsistency approach based on the number of detected boxes, we achieve the same mAP as the random sampling strategy with 50% of the labeled data.
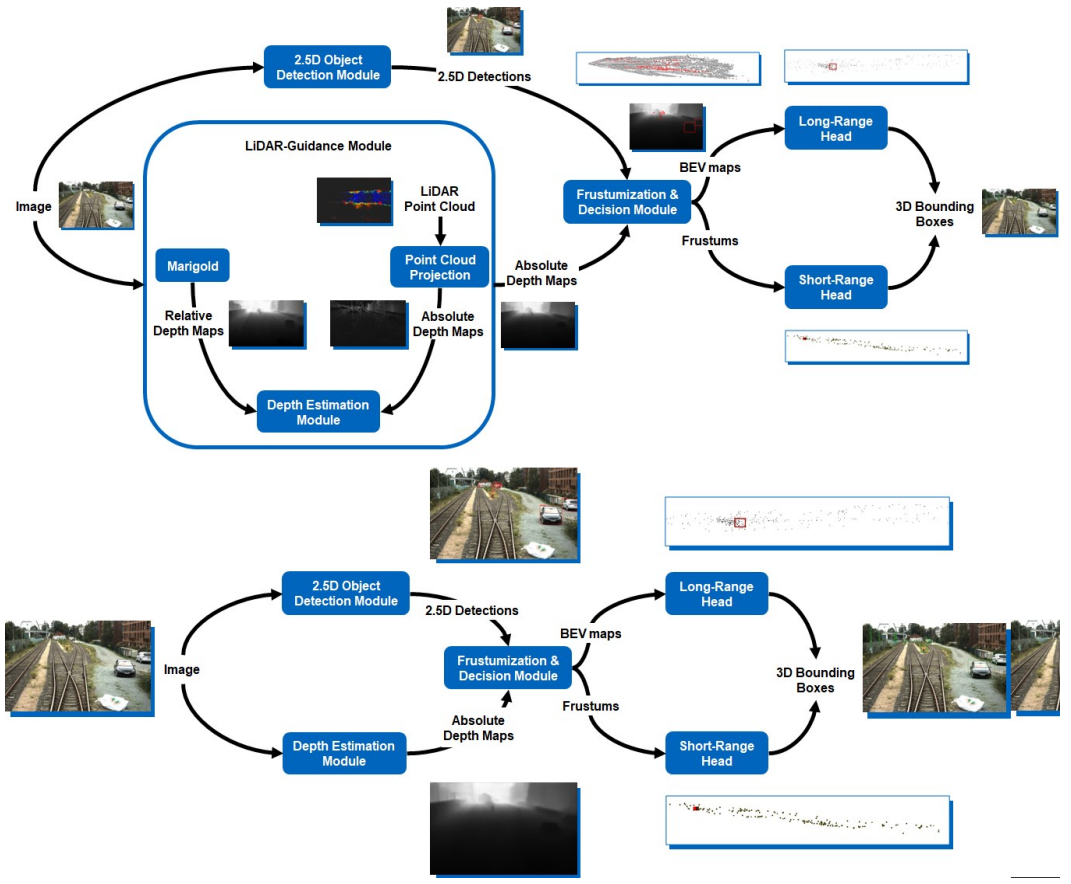
LiDAR-Guided Monocular 3D Object Detection for Long-Range Railway Monitoring
Authors: Raul David Dominguez Sanchez, Xavier Diaz Ortiz, Xingcheng Zhou, Max Peter Ronecker, Michael Karner, Daniel Watzenig, Alois Knoll
Affiliations:
SETLabs Research GmbH, Germany
Technical University of Munich, Germany
Graz University of Technology, Austria
Abstract: Railway systems, particularly in Germany, require high levels of automation to address legacy infrastructure challenges and increase train traffic safely. A key component of automation is robust long-range perception, essential for early hazard detection, such as obstacles at level crossings or pedestrians on tracks. Unlike automotive systems with braking distances of ~70 meters, trains require perception ranges exceeding 1 km. This paper presents an deep-learning-based approach for long-range 3D object detection tailored for autonomous trains. The method relies solely on monocular images, inspired by the Faraway-Frustum approach, and incorporates LiDAR data during training to improve depth estimation. The proposed pipeline consists of four key modules: (1) a modified YOLOv9 for 2.5D object detection, (2) a depth estimation network, and (3-4) dedicated short- and long-range 3D detection heads. Evaluations on the OSDaR23 dataset demonstrate the effectiveness of the approach in detecting objects up to 250 meters. Results highlight its potential for railway automation and outline areas for future improvement.